songwhip.com oldalt: megkeresi neked a tracket minden streaming music service-ben és kiteszi a linkjeiket egy listába. Ordít róla, hogy ebből Alfred workflowt kell csinálni (Ottó régóta kérte már ezt tőlem, plusz tök jó érzés pont pénteken kipipálni egy pet projektet). Csak egy kis Python kell hozzá XPath-tal és már ki is túrtuk a lényeget:
#!/usr/bin/python import sys, os, json, requests from lxml import html # get url from clipboard url = os.getenv('cb') query = 'https://songwhip.com/' + url page = requests.get(query) url = page.url tree = html.fromstring(page.content) data = { "items": [] } mods = { "cmd": { "subtitle": "Copy link to clipboard" }, "alt": { "subtitle": url } } song = tree.xpath('/html/head/title/text()')[0] data["items"].append({"valid": True, "uid": "00songwhip", "title": "SongWhip", "subtitle": song, "arg": url, "icon": {"path": "icon.png"}, "mods": mods}) items = tree.xpath('//a[@role="button"]') i = 0 for item in items: i = i + 1 title = item.text url = item.get("href") file_icon = "icons/icon.png" if os.path.isfile("icons/" + title + ".png"): file_icon = "icons/" + title + ".png" mods = { "cmd": { "subtitle": "Copy link to clipboard" }, "alt": { "subtitle": url } } data["items"].append({"uid": str(i).rjust(2,"0") + title, "title": title, "subtitle": song, "arg": url, "icon": {"path": file_icon}, "mods": mods}) sys.stdout.write(json.dumps(data))
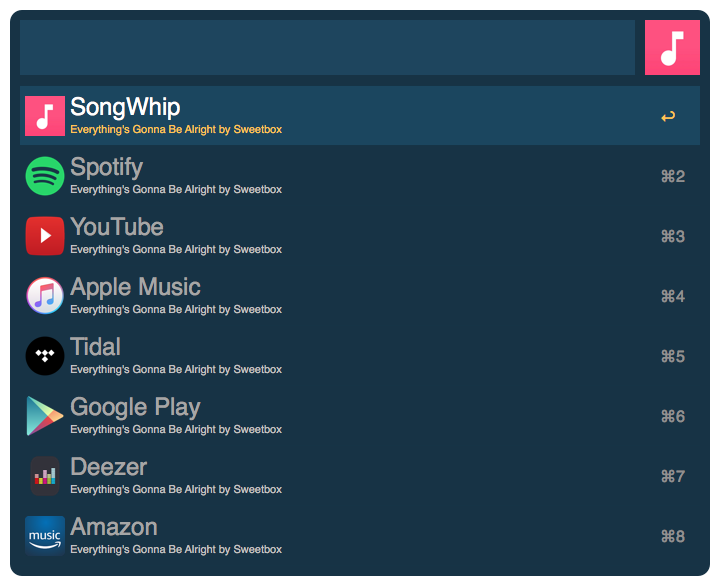 Ha tetszik, viheted a packal.org-ról. Have fun!]]>
Ha tetszik, viheted a packal.org-ról. Have fun!]]>